-
01. Ordinary Least Squares (OLS)경제학/실전압축계량경제학 2020. 4. 29. 04:29
실전압축계량경제학은 열심히 계량공부를하다가 기록으로 남기고픈 마음에 대충 정리해서 쓰는 글입니다.
글의 내용은 정확하지 않을 수 있으며 저는 책임 안집니다.
사진 출처는 교수님이니 무단전재와 재배포를 절대 금지합니다.
글 내용에 틀린점이 있으면 다른 사람들이 알 수 있도록 댓글을 남겨주세요.
계량경제학을 배우려면 배경지식으로다가 고등학교 확통 개념을 잘 알고있어야한다
행렬에 대해서도 알아야한다
엄청 어려운 행렬개념은 필요 없는거 같기도 한데
곱셈, rank같은거나 역행렬 같은거는 좀 알아야한다
경제수학에서 배운 내용들인데 기억이 날리가 없으니 시작하기전에 한번 복습을 하면 좋겠지만
그냥 모르는거 나올때마다 열심히 구글 검색해도 그럭저럭 할만하다
계량경제학은 Regression에 관한 학문이다
Regression이 뭐냐면 데이터를 이용해서 식을 만드는 거라고 생각하면된다
영어강의를 듣고 있어서 한국어로 된 용어는 잘 모른다
왜 이런 짓을 할까?? 데이터 속 변수의 상관관계에 대해서 잘 알고 싶으니까 그런거 아닐까?
아무튼 가장 단순한 Regression이

이런 모양이다
여기서 y는 regressand이나 dependent variable이라고 하고 B(베타)는 parameter라고 하고 x는 independent variable나 regressor 이라고 하고 e는 error이나 residual 이라고 한다
용어 같은거는 외우지 않으면 뒤 내용이 완전히 이해가 안되니까 무조건 외워라
이렇게 여러 문자들이 있는데 우리가 젤 궁금한거는 바로 B, 즉 파라미터이다
파라미터는 x의 계수라서 그 의미가 크기 때문이다
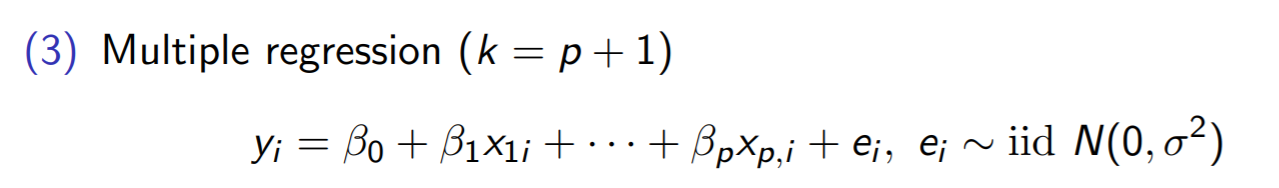
아무튼 이런식으로 regression은 변수가 엄청나게 많아질 수도 있다
변수가 많아지면 식 쓰기가 귀찮아지니까 벡터를 이용한다

이런식으로. 계량경제학에서는 행렬의 디폴트값이 column 벡터니까 (세로로 긴거) 헷갈리면 안된다

아무튼 벡터를 이용하면 이렇게 많은 변수를 간단한 식으로 (y=xB +e)로 나타낼 수 있다
알아둬야되는거는 벡터는 대문자 X이고 원소? 는 소문자 x인 점이다 애매하게 쓰다가 감점먹을 수도 있겠다...
우리가 앞으로 할 regression에는 기본적으로 5가지의 가정을 깔고 들어간다
이해하기 힘들다 나도 첨보고 이해가 안되서 알아보려고 원서를 읽어봤는데 읽을땐 이해가 되는가 싶다가도 덮으면 기억안나고 그런식이다
그러면 어떻게 해야한다? 5가지는 그냥 다 외워버려야 한다! 왜냐하면 오늘 푼 2011 중간고사 기출문제에 5가지 가정을 설명하세요가 있었기 때문이다 교수님 너무하시다
1. Strict Exogeneity

노란 밑줄이 특히 중요하니까 잘 외워둬라
에러의 평균은 0이라는 얘기다
2. Spherical Disturbances

에러의 분산은 시그마 제곱으로 항상 일정하다 (에러마다 분산이 달라지는걸 한국어로 이분산 이라고한다 =heteroskedasticity 구글에 검색하니까 heteroscedasticity로 나온것도 같았다 원래가 독일어인가?)
그리고 에러끼리 곱셈의 기댓값은 0이다
이게 먼얘기냐면 에러끼리는 공분산이 0이라는 얘기인데 서로 영향을 안미친다는 뜻임
3. X Full Column Rank
rank(X) = k 라는 얘기다
rank 성질 중에 rank(X)=rank(X'X)=k 가 있단다
그래서 X'X는 invertible한거다 (구글발 정보)
4. Linearity in Parameters
변수(x)간에 선형성이 있는게 아니라 파라미터 사이에 선형성이 있는 것이다
5. X is nonstochastic
X는 확률변수가 아니다 (e는 확률변수임)
이 5가지 가정이 기본빵이고 이 기본이 성립하지 않는 예외적인 문제들이 나오는데 그건 중간이후에 해결하는 방법을 설명해주겠다고 하셨다
그러니까 일단 잘 알고 있어야한다
드디어 MM estimator랑 OLS estimator가 나온다
MM estimator는

요 식에서 E(X'e) =0 이 되는 B값을 찾는 estimator이다. 0이 된다는건 X랑 e가 상관이 없다는 얘기다
OLS estimator는 e(에러)를 가장 최소화 하는 B값을 찾는 estimator이다.
MM이랑 OLS랑 조금 다른걸 알아야한다. 두개가 반대되는 내용은 아닌데 아무튼 방법이 다르기 때문이다
얼마나 다른게 사실 중요한건 아니고 두개가 결국엔 같은 resulting estimator를 갖고 있다는게 더 중요하다
왜 같은지 알아보자
BMM을 어떻게 구하나면

MM이 이 식을 만족하는 B를 구한다고 했다

기댓값을 시그마로 표현하면 이렇게 된다

X'B를 이항하면 e에 관한 식으로 정리할 수 있으니까

아까 시그마 식에 있는 e에 대입하면 이렇게 된다
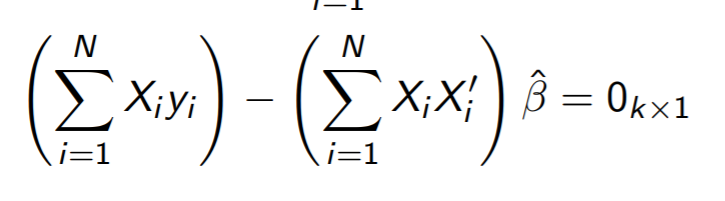
분배법칙 해주고 시그마 분리해낸다음

B만 남겨놓고 나머지를 이항하면 완성이다
그 다음은 OLS
Ordinary Least Squares의 약자이다
왜 ordinary인지 책에서 봤는데 까먹었다 말이 너무 어렵기 때문에 알고싶지도 않다
least는 젤 작다는 얘기고 square는 제곱이라는 뜻이니까 대충 젤 작은 제곱이라는 이야기다
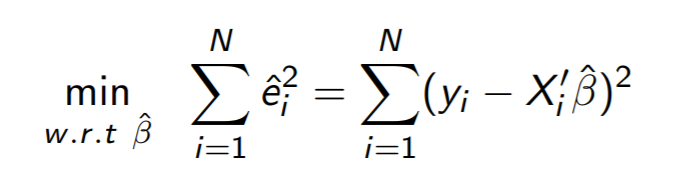
OLS는 e를 제일 작게 만드는 B라고 했는데 사실 e는 아니고 e^2 을 제일 작게 만드는 B이다
e위에 햇이 달렸다가 안달렸다가 B위에 햇이 달렸다가 안달렸다가 하는 이유는

모집단일때는 햇을 안달고 샘플일때만 햇을 달기 때문이다
우리가 주로 다루는건 샘플이니까 모르겠으면 그냥 일단 달고 보는 것도 방법이 아닐까?(책임안짐)
아무튼 다시 OLS로 돌아와서

시그마 e^2를 SSR이라고 부른다. SSR은 sum of squared residuals 의 약자이다
그렇다면 SSR을 가장 작게 만드는 B가 뭔지 어떻게 알 수 있을까?
중학교때 2차함수 배웠던 기억을 떠올려라
최솟값 구하기 위해서 멀 했었는지 기억이 나는가?
미분한 식 =0 되는 x값 구해가지고 원래 식에 대입하지 않았던가???
한번 미분한 식을 FOC라고 하는데
FOC=0 이 바로 e^2을 제일 작게 만들 조건인 것이다
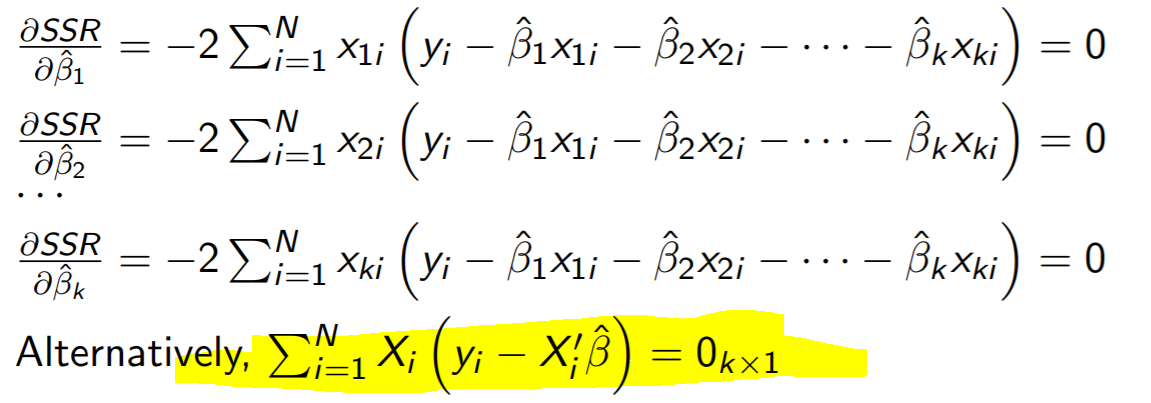
중딩때는 식에 변수가 x 하나밖에 없으니 한번만 미분을 해주면 됐었지만
regression에는 x1 x2 x3 x4 등등등 변수가 많다
그러면 각 변수로 식을 편미분시켜줘서 FOC를 구하고 FOC=0 을 만족하는 B값을 구해야하는 것이다
편미분이 먼지 모르겠으면 구글링하자 (경제수학때도 배웠음)
x들을 묶어서 칼럼벡터 X로 표현한 것이 노란색으로 칠해논 부분이다
이제 저 식을 B에 관한 식으로 정리를 해줘야 한다

분배법칙해주고
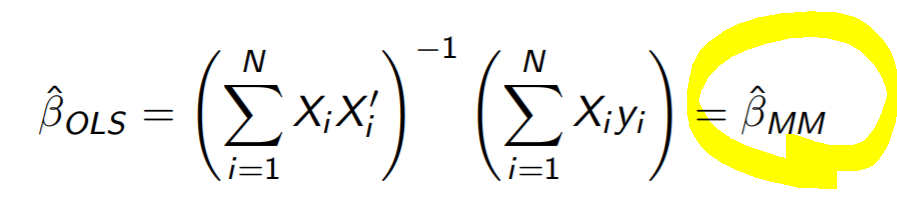
B빼고 나머지 다 이항해주면 완성이다
근데 띠용? 아까 봤던 BMM이랑 똑같은 식이 되어버렸다!

그 이유는 바로 OLS의 FOC인 이 식이
MM이랑 똑같기 때문이다
매우 중요한 부분이니까 까먹지 말자

마지막으로 시그마를 벡터로 표현하는 법을 소개하겠다
이런식으로 된다... 행렬의 곱셈을 해보면 알 수 있다
하지만 계속해서 나오는 표현이니까 바로바로 튀어나올 수 있도록 달달달달 암기를 해둬야한다
참고) X는 Nx1 칼럼벡터고 X'는 X의 전위행렬으로 1xN 로우벡터다
찐막으로 몇가지 쉬운 개념을 배우자
Fitted value 라는 용어가 나온다
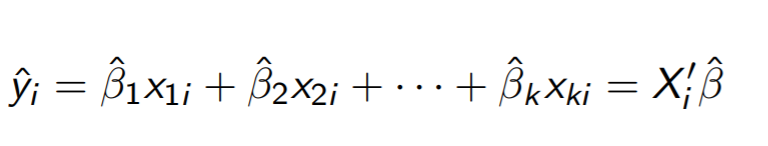
라고 가르쳐 주셨는데 아마 y에서 e를 뺀 부분을 fitted value라고 하는 것 같다

출처:https://freshrimpsushi.tistory.com/650
적합치, 예측치, 잔차, 오차 Fitted Value, Predict Value, Residual, Error
회귀분석 $Y \leftarrow X_{1} + X_{2} + \cdots + X_{n}$ 으로 얻은 회귀식을 $y = \beta_{0} + \beta_{1} x_{1} + \beta_{2} x_{2} + \cdots + \beta_{n} x_{n} $ 이라고 하고 $i$ 번째 데이터를 $(y_{i} , x_{i..
freshrimpsushi.tistory.com
Residual이란 용어도 나온다

residual은 맨 첨에 파라미터랑 독립변수 independent variable 이런거 설명할때도 한번 나왔었다
시그마 제곱을 추정할 때 B를 알고 있을 때 하고 모르고 있을 때 식이 달라진다
B를 알고 있으면

모르고 대신 B햇 (샘플의 B)만 알고 있는 경우
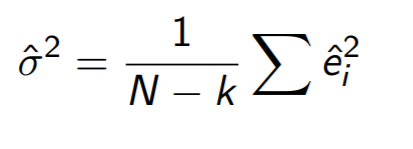
N대신 N-k를 쓰는 이유는 고딩 확통 배울 때 표본평균이랑 분산 구할때 N대신 N-1 쓰던 거랑 연관 지어서 생각하면 될 것 같다
내가 알기론 N으로 나누는 것보다 N-k로 나누는게 추정값이 더 정확해서 N-k 쓰는 걸거임
왜 이렇게 대충 설명하고 넘어가냐면 아직 이거 관련 문제를 본적이 없다 관련 문제 나오면 다음에 공부하고 강조해드림
끝. 글이 너무 길어져서 2편 쓸 엄두가 안난다! 200429 오전4:29 씀
'경제학 > 실전압축계량경제학' 카테고리의 다른 글
계량경제학 중간고사 공략4 (0) 2020.06.01 계량경제학 중간고사 공략3 (0) 2020.05.28 계량경제학 중간고사 공략2 (0) 2020.05.24 계량경제학 중간고사 공략1 (0) 2020.05.23 02. OLS part2 (0) 2020.04.29