-
계량경제학 기말고사 문제풀이경제학/실전압축계량경제학 2020. 7. 10. 00:42
중간고사가 4개나 더 남아있다
2016, 7, 8, 9
지금까지 잘 따라왔다면 남은 것들도 아마 잘 풀어낼 수 있다

원래는 기말고사가 대면시험이었는데
코로나 재확산으로 기말고사도 과제제출로 대체되었다
다행히 이번에는 교수님이 8개년치 기출 풀어오기가 아닌
새로운 문제 10개를 풀어오기를 내주셨다

요약: 중간고사 대비 기말고사 과제의 점수 평균이 낮아졌다
a+ 또는 a를 맞은 사람은 전체의 53퍼센트이다
기말고사 과제의 평균값은 10.66 최고점은 30.15 중앙값은 8.78이다
그렇다면 내 점수는??"?

아무튼 나는 a+ 받았음 ㅋㅋ
그럼 이제 기말고사 문제를 대충 풀어보자

1번과 2번은 매트랩 코드를 쓰는 문제다
매트랩을 쓸 필요가 없으면 그냥 넘겨도 된다
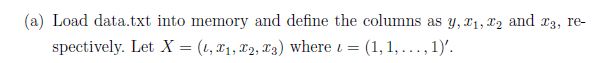
데이터를 로드하고 변수를 선언해라

맨 윗줄은 안써도 된다 명령창 깨끗이 하는 거니깐
ones()가 1로 이루어진 행렬임

F test를 해야된다
귀무가설H0을 R을 이용해서 다시 정리해야하는데

교수님 자료 이런식으로 한쪽으로 다 이항해서 어쩌고 =0 꼴로 만든다음에 Rb-r=0 꼴로 바꿔야한다
F test가 많이 복잡하니까 RRSS랑 URSS를 먼저 선언해두고 나중에 이용하면 편하다

Ftest안에 J랑 k가 있는데 이게 뭘 의미하는지 잘 파악해서 J도 선언하고 k도 선언하자
J는 R의 행의 갯수 // k는 x의 열의 갯수
finv가 뭐냐면

출처 교수님 이거라고 가르쳐주셨다
해보면 fc가 더 커서 귀무가설 기각 못함

F test의 2번째 형태이다

F가 또 복잡하니까 괄호별로 따로 선언해서 이용했다

이렇게 정의했다
위에꺼랑 ftest 값이 같아야한다

2번은 실제 데이터로 계수들을 구하고 테스트하는 방법을 묻고있다

b는 어떻게 구할까요
b를 구할라면 y도있어야하고 아무튼 다 선언되어있어야하는데
교수님이 대뜸 b를 구하세요라고 해서 잘 실감이 안되니까

그냥 데이터 있다고 치고 다 선언한 다음에 b를 구하는 식을 썼다 ols 이용해서
위에 여섯줄은 안써도 될지도 모른다

t value는 어떻게 구할까
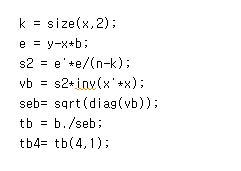
t value는 베타를 b의 standard error로 나눠주면 된다
standard error를 구하려면 분산값을 알아야하고 그거 알려면 시그마제곱이 뭔지 알아야한다
그래서 e부터해서 선언해서 마침내 b의 t value를 구했다
근데 문제에서 b4의 t value를 구하랬으니 tb 중에서도 4번째 줄에 있는 값 tb(4,1)이 정답이다

여자고 백인아니고 조합원이 아니면???

dummy variable 이 0인지 1인지 구별하는 문제다

이번에는 interactive variable이었나 아무튼 성별X연차를 변수로 만들면 된다

그래서 새로운 x인 xxx를 만들어서 b를 구하면 된다
매트랩 clear

(a): mle가 unbiased하고 시그마제곱이 biased한걸 증명하세요
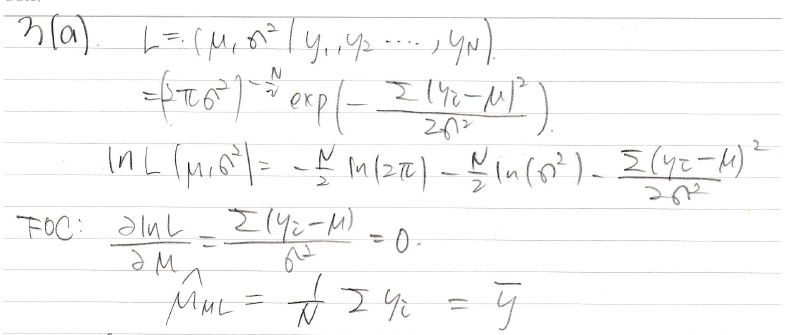
mle가 뭔지 간략히 설명했다
일계도함수 foc 계산하는 방법은 교수님이 모르면 패스하랬음
그래서 중간 과정없이 강의자료대로 베껴 썼다

그래서 mle를 구해보니 ols랑 형태가 똑같다
ols는 가우스 마르코브 이론에 따르면 BLUE이니까 ml도 불편향이다
y빠 (y의 평균)에 기댓값도 y빠라 불편향 맞다
이번에는 시그마제곱
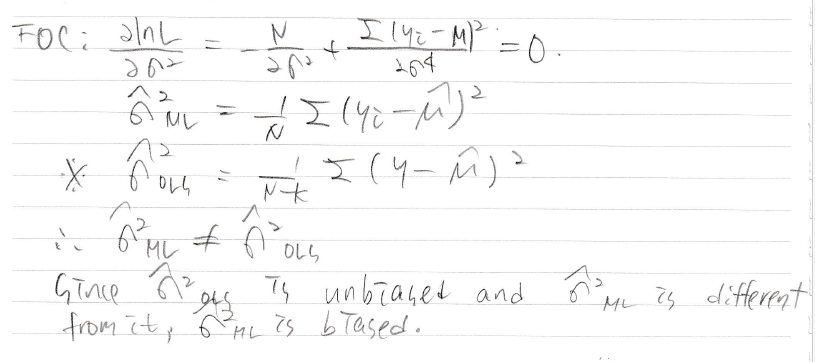
Likelihood function인 L을 시그마 제곱으로 미분한걸 0이라고 두면 (FOC)
시그마제곱ml을 구할 수 있고
구해보니 ols랑 달라서 얘는 편향이겠구나~ 결론지었다

mle가 이번에는 efficient한거랑 s2이 불편향이지만 CRLB를 만족하지 못한다는 것을 보이란다
efficient하다는 걸 어떻게 증명할까? CRLB를 구해서 var(뮤ml)이 CRLB랑 같음을 보이면 되겠다
그렇다면 CRLB를 먼저 구하자

이런식으로 CRLB를 구했다
그 다음에는 뮤ml의 분산을 구해야하는데 뮤ml이랑 뮤ols랑 아까 같다는 걸 알았으니까
원래 알고 있었던 뮤ols 분산을 뮤ml 분산 대신 쓰도록 하자

CRLB랑 같은가?
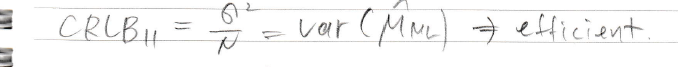
같다
그다음 s2의 불편향 이거는 중간고사 때 많이 해봤다
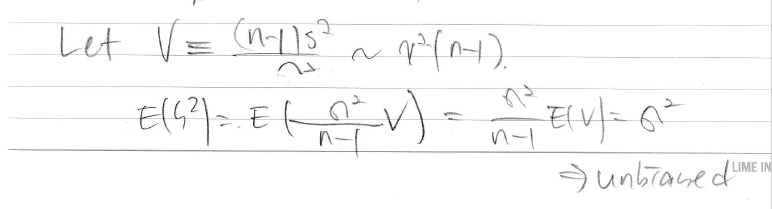
불편향임
s2의 분산도 구해봤다

CRLB는 분모가 N-1이 아니라 N이라서 s2의 분산보다 작다
그래서 CRLB 실패
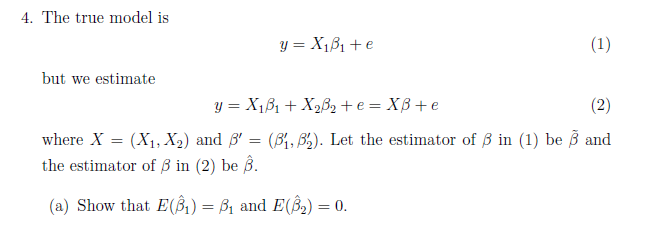
x2가 없는데 있다고 착각한 경우이다 extraneous variable인가 단원명이 그랬던것같은데
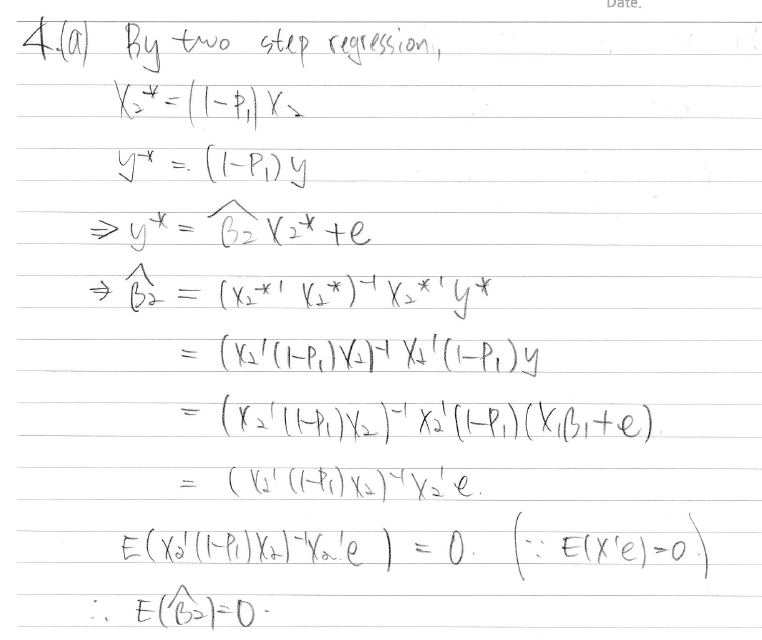
two step regression을 쓰라고 가르쳐주셨다
투스텝하니 생각나는데 예전 게시글에 내가 two step이랑 two stage랑 같다고 한 것 같은데 두개가 다른거였다
2sls가 2 stage인데 2step이랑 미묘하게 다르니까 어디가서 두개가 같은거라고 하면 무식해보이니 조심하자
아무튼 b2의 기댓값은 0임

같은방식으로 b1의 기댓값을 구해보면 이번에는 b1이 나온다
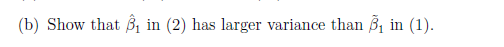
이번에는 두개의 분산을 비교하라는 문제다

저번에 틀렸을 것 같다던 R-squared 문제도 이런식으로 비교했으면 더 좋은 점수 받았을 것 같은데 아쉽다
시그마 tilde가 ... tilda가 아니었다 이것도 착각하고 있었음
이딴식으로 나오길래 대충보고 tilda가 맞는 줄 알았는데...
자세히보면 착각ㄴ이라고 써있음

아무튼 다시 돌아와서 큰거끼리 곱한게 당연히 작은거끼리 곱한것보다 같거나 크므로

시그마 햇 제곱이 더 크다
+왜 저게 더 큰가요?

이게 성립해서요

타입2에러가 왜 커질까요?

분산이 커진다 -> t분포 꼬리가 두꺼워진다 -> 임계값이 커진다 -> 기각하기 어려워진다 = 타입2에러

x1에 에러가 포함되는 경우 어떻게 해야하나
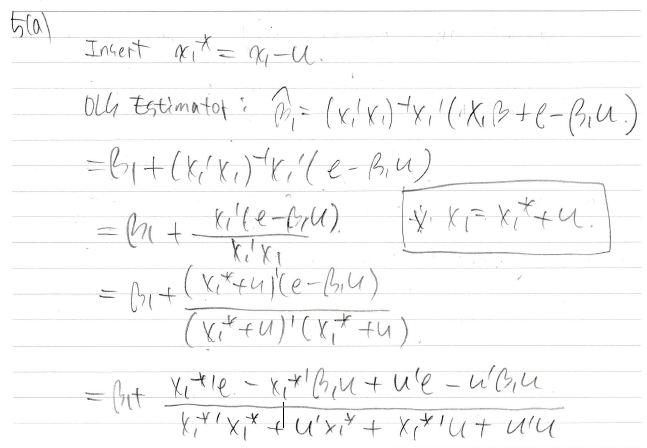
inconsistent한걸 보이기 위해 일단 b를 구한다
예전에 ols 했을 때 consistent한거 증명할때 y를 원래 식으로 바꿔줬듯이 이번에도 바꿔준다

이걸 참고해서 확률수렴하면

이렇게 된다 베타앞에 이상한 계수가 달렸기 때문에 원래 b1이랑은 달라지는 것
그래서 inconsistent

1. error가 엄청클 때

시그마제곱u가 커짐 -> 분모 커짐 -> 0으로 수렴
2.아예없을 때

시그마제곱u가 0이 됨 -> 분모분자 약분됨 -> b1이랑 똑같아짐

b1을 consistent하게 만들려면 어째야 하나

여러 가정들을 추가하면 된다
x랑 u랑 독립이고 w랑도 독립이면 적어도 consistent한 값을 얻을 수 있음
아니면 틀린 관측값 쓰지 말고 적당한 값을 쓰던가...

문제의 6번
결과를 보고선 해석하는 문제인데
내가 잘 안들었나 교수님이 휘리릭 가르쳐주셨나 모르겠지만 잘 몰라서 야매로 해석했음

lagged value를 쓰는 이유? x 사이에 연관성이 있을까봐 비교적 상관없는 옛날 값을 쓴다
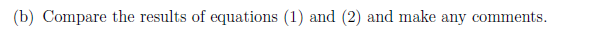
1번2번보고 느낀점을 쓰시오

f값이 줄었네? x가 더 좋아졌나보다
t값도 5% 유의수준에서 괜찮다니... 이자율은 꽤 괜찮은 x일지도? 랄까..
=> 자신없음
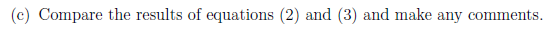

f값 올랐어? x가 구려졌다
t값도 유의수준 밖이야? 새로운게 별로 맞네
=> 자신없음222
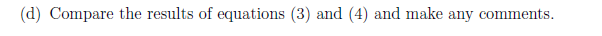

f값 줄었어? x가 좋아졌다
어 근데 t값보니 유의수준 밖이야? hoxy ... multicollinearity 문제 아닐까?
=> 자신없음333

헤테로스케데스티시티문제 heteroskedasticity 인듯

시그마= TT'라고 하자

새로만든 y*으로 ols 를 하면 고걸 b gls라고 한다
중간에 시그마가 껴있는게 특징임
b gls의 편향을 알아보기 위해 기댓값을 구해보면 b가 나온다 ->불편향
그 다음 variance covariance matrix 구하는법


변수 갯수보다 식 갯수가 더 많은 경우
모든 식이 만족되지 않을 수 있다
그럴 땐 어떻게 해야할까
그냥 쓰고 싶은 식만 골라 쓰는 것도 방법이지만 그러면 너무 지맘대로같으니까

프로젝션을 이용한다
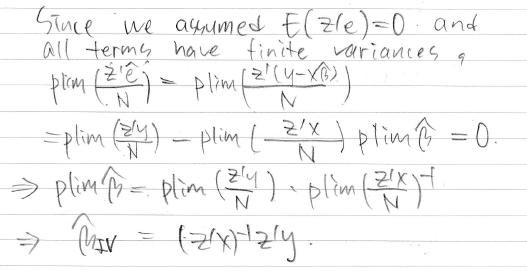
생각해보니 b iv를 구하는 법을 설명을 안해서 b iv 구하는 법을 설명했다

아까 구해둔 x햇을 z대신에 쓴게 이제 l이 k보다 클 때의 상황이다
근데 x햇을 z랑 x로 바꿔보면 결국 약분되어 사라지고 원래 식만 덩그러니 남는다
원래식이 남는다는 말은? 프로젝션을 이용하면 원래랑 같은 값을 구할 수 있다 (?)

2sls 하는 법을 먼저 알아야지 같은지 안같은지 알 수 있겠죠?
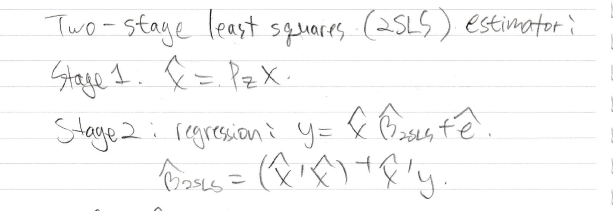
이런식으로 이뤄집니다
근데 아까 구한

첫번째 줄 식을 잘 변형하면 2sls 처럼 만들 수 있습니다
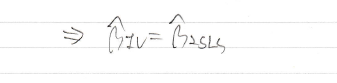

분포수렴 하라는 말 같다

참고사항을 잘 이용해서 분포수렴 하면 된다
외우는 부분이니까 pass

둘이 무슨 사이야?
GMM이 뭔지 알아야 얘길하지

이건데 그래서 b GMM이 뭔데

FOC를 이용하면 이렇게 x랑 z랑 w랑 y를 이용해서 표현할 수 있다

근데 갑자기 optimal weight를 이용하면?

GMM이 2sls 모양으로 바뀜
결론은 optimal weight를 이용한 GMM이 2sls 였던 것

멀티콜리니어리티를 어떻게 알 수 있을까?
열심히 강의자료를 베껴쓰면 된다

1번 제로 오더 코릴레이션 이용하기

2번 부분 회귀식 이용하기

그것도 싫으면 3번 f test 이용하기
계량 경제학 끝!
생소한 수학 개념이라 어려웠던 점도 많았지만 매트랩도 써보고 회귀식이라는 것도 배워보고
나름 유익하고 재밌는 시간이었다
사실 중간고사 점수가 좋아서 기말고사 과제는 부담없이 했다
그래서 설명도 짧고 틀린 것도 많을 수 있으니 이걸 보는 사람이 이해해줬으면 좋겠다
아무튼 나는 다음 주에 군대간다 ㅋㅋ 모두 군바
完
'경제학 > 실전압축계량경제학' 카테고리의 다른 글
계량경제학 중간고사 공략4 (0) 2020.06.01 계량경제학 중간고사 공략3 (0) 2020.05.28 계량경제학 중간고사 공략2 (0) 2020.05.24 계량경제학 중간고사 공략1 (0) 2020.05.23 02. OLS part2 (0) 2020.04.29